
ELECTRONICO Scraping: Making Present day File Formats More Obtainable
Data scraping is the method of instantly sorting through data contained on the internet within html, PDF or other paperwork and collecting relevant information to into databases and spreadsheets for later on retrieval. On most internet sites, the textual content is effortlessly and accessibly prepared in the resource code but an escalating variety of firms are employing Adobe PDF structure (Portable Doc Format: A structure which can be considered by the free Adobe Acrobat computer software on nearly Lead Generation any running technique. See below for a website link.). The gain of PDF format is that the document seems to be specifically the same no issue which computer you view it from creating it best for business varieties, specification sheets, and so forth. the drawback is that the text is transformed into an impression from which you typically cannot effortlessly duplicate and paste. PDF Scraping is the method of information scraping info contained in PDF data files. To PDF scrape a PDF doc, you must make use of a much more varied established of instruments.
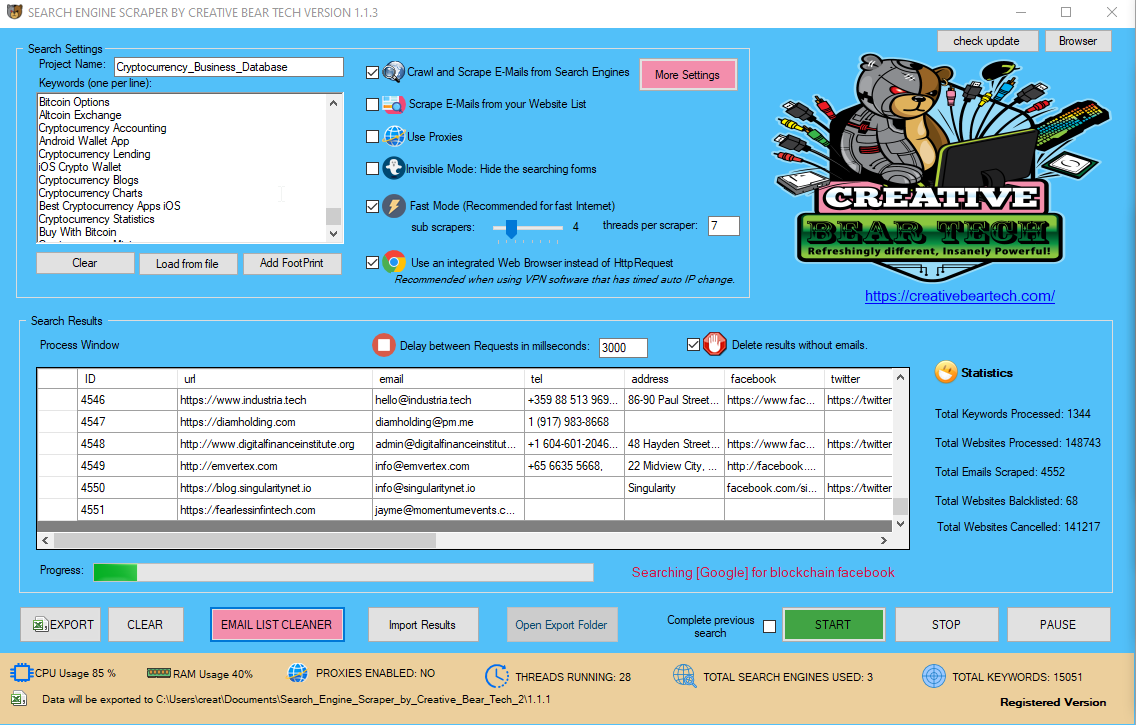
There are two main kinds of PDF documents: individuals constructed from a textual content file and those developed from an graphic (very likely scanned in). Adobe’s very own application is capable of PDF scraping from text-based mostly PDF documents but special tools are necessary for PDF scraping textual content from image-based PDF data files. Email Extractor for PDF scraping is the OCR plan. OCR, or Optical Character Recognition, programs scan a document for modest pictures that they can independent into letters. These photographs are then in comparison to true letters and if matches are discovered, the letters are copied into a file. OCR applications can perform PDF scraping of impression-based mostly PDF information really correctly but they are not perfect.
When the OCR plan or Adobe system has finished PDF scraping a doc, you can research via the knowledge to locate the parts you are most interested in. This info can then be stored into your preferred databases or spreadsheet software. Some PDF scraping applications can form the knowledge into databases and/or spreadsheets instantly producing your occupation that considerably simpler.
Fairly usually you will not find a PDF scraping program that will obtain exactly the information you want without customization. Remarkably a search on Google only turned up one enterprise, (the amusingly named ScrapeGoat.com http://www.ScrapeGoat.com) that will create a tailored PDF scraping utility for your task. A handful of off the shelf utilities claim to be customizable, but seem to be to demand a little bit of programming information and time dedication to use properly. Acquiring the info oneself with 1 of these tools might be achievable but will likely prove fairly tedious and time consuming. It may possibly be recommended to agreement a company that specializes in PDF scraping to do it for you quickly and skillfully.
Let us discover some actual world illustrations of the uses of PDF scraping engineering. A group at Cornell College wished to enhance a database of technological documents in PDF format by using the outdated PDF file the place the hyperlinks and references had been just photographs of textual content and shifting the backlinks and references into working clickable hyperlinks as a result generating the database easy to navigate and cross-reference. They utilized a PDF scraping utility to deconstruct the PDF data files and figure out where the hyperlinks have been. They then could create a simple script to re-generate the PDF data files with operating links changing the previous text impression.
A personal computer components seller desired to display technical specs information for his hardware on his web site. He hired a organization to complete PDF scraping of the hardware documentation on the manufacturers’ site and save the PDF scraped knowledge into a database he could use to update his webpage instantly.
PDF Scraping is just gathering information that is available on the community internet. PDF Scraping does not violate copyright legal guidelines.
PDF Scraping is a fantastic new technological innovation that can significantly lessen your workload if it requires retrieving info from PDF data files. Purposes exist that can assist you with scaled-down, less difficult PDF Scraping projects but companies exist that will create personalized applications for more substantial or far more intricate PDF Scraping employment.